GHC LLVM LTO Experiments Scratch Notes
Last updated: Dec 17, 2022
*This is a followup to this previous post where I play with GCC’s link-time optimization in GHC-compiled programs. I note there that this is limited since it only works on sources compiled from C (crucially the RTS). Here I’ve compiled rough notes doing the same thing with LLVM LTO, where I attempt to get true whole-program optimization *cooking.
The goals were to play with some new tech and possibly discover some significant performance gains (without thinking very hard) that could be ported back or realized in a less hacky way. Results were underwhelming and so I don’t do much real digging into assembly (the other thing besides good results that would have made for an interesting post). So after waffling I decided to basically dump my notes here, lightly edited, in case it’s helpful to someone who wants to take up similar work later.
The GHC branch with scratch work is also a mess since it took a lot of fiddling and some manual intervention (below) before a full build completed. If you’re really interested in this work shoot me an email and I can try to help.
Building GHC for LLVM LTO
I used shims as before to quickly manipulate clang, lld, etc for LTO. The first issue a ran into
was that symbols StgReturn and StgRun (both defined with inline asm) weren’t making it into the
RTS library archive (in particular StgCRun.thr_o), possibly due to dead-code elimination; note all
objects are actually LLVM bitcode, not native object code.
I worked around this by adding the functions back directly to the LLVM IR which was quite nasty. See commit message.
The next big issue was we weren’t able to produce LLVM IR bitcode from haskell code (e.g. in
libraries) due to the LLVM mangler
which fiddles directly with assembly, and is supposedly necessary for tables-next-to-code.
Normally this is what happens when you compile with -fllvm
opt-6.0 -O2 -enable-tbaa -tbaa '-relocation-model=static' hello.ll -o /tmp/ghc15832_0/ghc_2.bc
llc-6.0 -O2 -enable-tbaa '-relocation-model=static' '-mcpu=x86-64' '-mattr=+sse2,+sse' /tmp/ghc15832_0/ghc_2.bc -o /tmp/ghc15832_0/ghc_3.lm_s
*** LLVM Mangler
clang -fno-stack-protector -DTABLES_NEXT_TO_CODE -iquote. -Qunused-arguments -x assembler -c /tmp/ghc15832_0/ghc_4.s -o hello.o
Linking blaaaah.lto ...
*** C Compiler:
clang -fno-stack-protector -DTABLES_NEXT_TO_CODE -c /tmp/ghc15832_0/ghc_5.c -o /tmp/ghc15832_0/ghc_6.o ...
*** C Compiler:
clang -fno-stack-protector -DTABLES_NEXT_TO_CODE -c /tmp/ghc15832_0/ghc_8.s -o /tmp/ghc15832_0/ghc_9.o ...
*** Linker:
clang -fno-stack-protector -DTABLES_NEXT_TO_CODE -o blaaaah.lto -lm -Wl,--gc-sections hello.o ...
link: done
But I found an (undocumented/experimental?) flag -fast-llvm,
that bypasses the mangler like so:
opt-6.0 -O2 -enable-tbaa -tbaa '-relocation-model=static' hello.ll -o /tmp/ghc18922_0/ghc_2.bc
llc-6.0 -O2 -enable-tbaa '-relocation-model=static' '-filetype=obj' '-mcpu=x86-64' '-mattr=+sse2,+sse' /tmp/ghc18922_0/ghc_2.bc -o hello.o
Linking blaaaah.lto ...
*** C Compiler:
clang -fno-stack-protector -DTABLES_NEXT_TO_CODE -c /tmp/ghc18922_0/ghc_3.c -o /tmp/ghc18922_0/ghc_4.o ...
*** C Compiler:
clang -fno-stack-protector -DTABLES_NEXT_TO_CODE -c /tmp/ghc18922_0/ghc_6.s -o /tmp/ghc18922_0/ghc_7.o ...
*** Linker:
clang -fno-stack-protector -DTABLES_NEXT_TO_CODE -o blaaaah.lto -lm -Wl,--gc-sections hello.o ...
So I manually added -fast-llvm to all the cabal files in the GHC tree, shimmed llc-6.0 to be
just a cp (so hello.o stays an LLVM IR bitcode that can participate in LTO).
It’s not clear to me why the mangler doesn’t seem to actually be necessary (for the binaries I tested, on my machine).
The shims contained a fallback to compiling to object code, but eventually I got a GHC source tree of mostly LLVM bitcode:
$ for f in `find libraries -name '*.o'`; do grep -q LLVM <(file "$f") && echo "$f"; done 2>/dev/null | wc -l
1230
$ for f in `find libraries -name '*.o'`; do grep -q ELF <(file "$f") && echo "$f"; done 2>/dev/null | wc -l
93
Experiments
I played with a few things in addition to just LTO (again timing hlint).
PGO
This was basically the same process as before, using AutoFDO. It wasn’t clear if it was really working as well as it could. Got a lot of warnings like:
ld.lld: warning: No debug information found in function r3UWn_info$def: Function profile not used
ld.lld: warning: No debug information found in function r3UUK_info$def: Function profile not used
ld.lld: warning: No debug information found in function hlintzm2zi0zi12zminplace_HintziPattern_zdwpatternHint_info$def: Function profile not used
Should have tried again with -fprofile-sample-accurate which treats functions with no call data as
cold rather than unknown. This isn’t in clang 6, but I learned later that newer clang/LLVM seem to
work pretty well with IR from GHC’s LLVM backend.
POLLY
POLLY is a research optimization framework targeting LLVM IR and which is
included/installed by default with my llvm-6 distribution, and it’s straightforward to try from
opt or clang.
As an aside, to see what opt -polly (or other flags) actually does, you can do:
$ touch fake
$ opt fake -O3 -polly -debug-pass=Arguments # and compare to...
$ opt fake -O2 -debug-pass=Arguments
It’s a bit sketchy since optimization passes are not generally idempotent, but I decided to just run
opt -O3 -polly over all the (optimized) LLVM IR in the GHC tree and ~/.cabal/store. There are a
couple scripts for unpacking/repacking library archives
in the SHIMS directory, if you ever need something like that.
Souper
An experimental tool from google that was annoying to install but actually pretty straightforward to use. It tries to discover new peephole-style optimization opportunities using an SMT solver (there’s like a whole paper and stuff), so it’s more something for compiler writers rather than something to include in an application compilation pipeline.
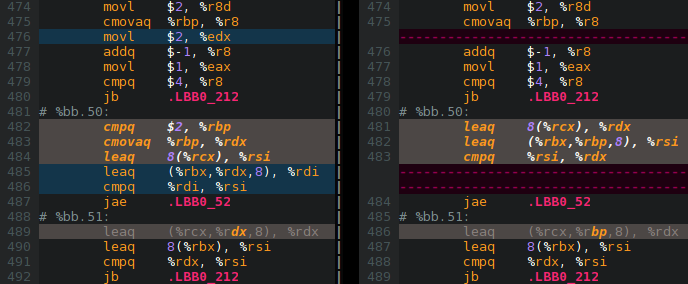
I first focused on Evac.c, a hotspot in the RTS. This found a few optimizations:
$ souper -z3-path=/home/me/.local/bin/z3 Evac_thr.thr_o
Ran much longer and found a few more:
$ souper -z3-path=/home/me/.local/bin/z3 -souper-exhaustive-synthesis Evac_thr.thr_o
Here’s one example picked at random that you can stare at for a while:
Timing Results
Again an hlint run over the lens code tree, like:
hlint lens-4.17 --report=/dev/null -q --threads=4 +RTS -s -A32M
-
Stock GHC 8.6 (native codegen):
30,029,597,382 instructions 3.577023660 seconds time elapsed -
Stock LLVM (stock ghc + fllvm)
29,361,619,562 instructions:u ( +- 0.45% ) 3.412444661 seconds time elapsed ( +- 1.49% ) -
LLVM LTO after successfully compiling
librariesto LTO objs:28,858,041,897 instructions:u ( +- 0.03% ) 3.372028439 seconds time elapsed ( +- 0.19% ) -
LLVM LTO (-O3):
27,912,731,892 instructions:u ( +- 0.17% ) 3.330403689 seconds time elapsed ( +- 1.00% ) -
First attempt at PGO (lots of warnings about lack of profile data (mangling issue?)):
27,965,192,528 instructions:u ( +- 0.25% ) 3.396919779 seconds time elapsed ( +- 1.97% ) -
PGO with O3:
27,882,344,880 instructions:u ( +- 0.06% ) 3.332535151 seconds time elapsed ( +- 0.88% ) -
LLVM LTO O3 + POLLY:
27,509,027,644 instructions:u ( +- 0.41% ) 3.370770830 seconds time elapsed ( +- 1.51% ) -
LLVM LTO O3 + Souper over full cabal new-build:
27,799,718,133 instructions:u ( +- 0.18% ) 3.292543353 seconds time elapsed ( +- 0.73% ) -
LLVM LTO O3 + souper on Evac (RTS):
27,905,099,478 instructions:u ( +- 0.16% ) 3.308439822 seconds time elapsed ( +- 0.47% )
Stripped hlint executable sizes for LLVM lto experiments…
20945776 llvm_lto
20966256 llvm_lto_pgo1
21113712 llvm_lto_O3
21336792 llvm_lto_souper_evac_lld9
21349120 llvm_lto_O3_souper_all
21349184 llvm_lto_O3_souper_all_exhaustive
21357304 llvm_lto_souper_evac
22039256 llvm_lto_polly
…and for previous gcc LTO work:
22415344 lto_pgo
22423424 lto_Os
22431616 lto_basic_O2
22431616 lto_march_native
22431616 lto_march_native2
22431616 lto_march_native_O3
22432216 gcc_stock
24612696 llvm_stock