Announcing unagi-chan
Last updated: Dec 11, 2022
Today I released version 0.2 of unagi-chan, a haskell library implementing
fast and scalable FIFO queues with a nice and familiar API. It is
available on hackage
and you can install it with:
$ cabal install unagi-chan
This version provides a bounded queue variant (and closes
issue #1!)
that has performance on par with the other variants in the library. This is
something I’m somewhat proud of, considering that the standard
TBQueue
is not only significantly slower than e.g. TQueue, but also was seen to
livelock at a fairly low level of concurrency (and so is not included in the
benchmark suite).
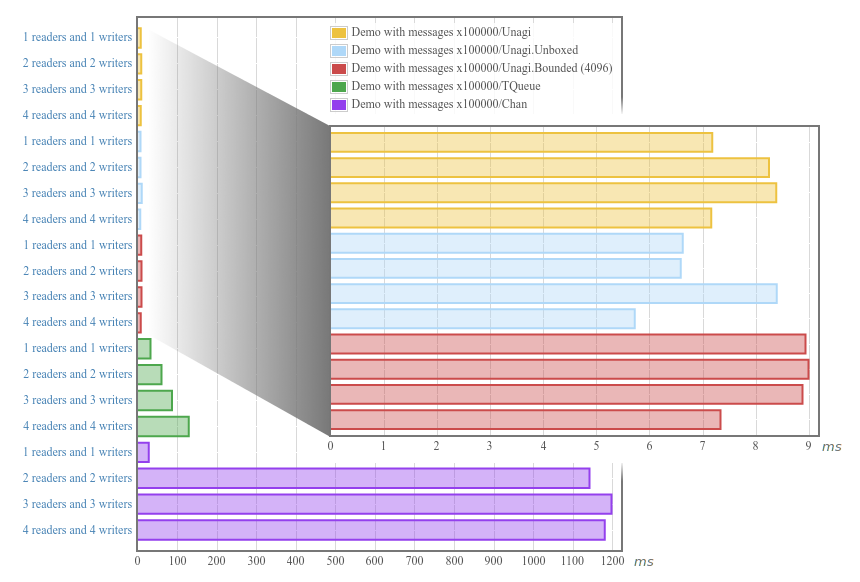
Here are some example benchmarks. Please do try the new bounded version and see how it works for you.
What follows are a few random thoughts more or less generally-applicable to the design of bounded FIFO queues, especially in a high-level garbage-collected language. These might be obvious, uninteresting, or unintelligible.
What is Bounding For?
I hadn’t really thought much about this before: a bounded queue limits memory consumption because the queue is restricted from growing beyond some size.
But this isn’t quite right. If for instance we implement a bounded queue by
pre-allocating an array of size bounds then a write operation need not
consume any additional memory; indeed the value to be written has already
been allocated on the heap before the write even begins, and will persist
whether the write blocks or returns immediately.
Instead constraining memory usage is a knock-on effect of what we really care about: backpressure; when the ratio of “producers” to their writes is high (the usual scenario), blocking a write may limit memory usage by delaying heap allocations associated with elements for future writes.
So bounded queues with blocking writes let us:
- when threads are “oversubscribed”, transparently indicate to the runtime which work has priority
- limit future resource usage (CPU time and memory) by producer threads
We might also like our bounded queue to support a non-blocking write which
returns immediately with success or failure. This might be thought of
(depending on the capabilities of your language’s runtime) as more general than
a blocking write, but it also supports a distinctly different notion of
bounding, that is bounding message latency: a producer may choose to drop
messages when a consumer falls behind, in exchange for lower latency for future
writes.
Unagi.Bounded Implementation Ideas
Trying to unpack the ideas above helped in a few ways when designing
Unagi.Bounded. Here are a few observations I made.
We need not block before “writing”
When implementing blocking writes, my intuition was to (when the queue is “full”) have writers block before “making the message available” (whatever that means for your implementation). For Unagi that means blocking on an MVar, and then writing a message to an assigned array index.
But this ordering presents a couple of problems: first, we need to be able to handle async exceptions raised during writer blocking; if its message isn’t yet “in place” then we need to somehow coordinate with the reader that would have received this message, telling it to retry.
By unpacking the purpose of bounding it became clear that we’re free to block
at any point during the write (because the write per se does not have the
memory-usage implications we originally naively assumed it had), so in
Unagi.Bounded writes proceed exactly like in our other variants, until the
end of the writeChan, at which point we decide when to block.
This is certainly also better for performance: if a wave of readers comes along, they need not wait (themselves blocking) for previously blocked writers to make their messages available.
One hairy detail from this approach: an async exception raised in a blocked
writer does not cause that write to be aborted; i.e. once entered, writeChan
always succeeds. Reasoning in terms of linearizability this only affects
situations in which a writer thread is known-blocked and we would like to abort
that write.
Fine-grained writer unblocking in probably unnecessary and harmful
In Unagi.Bounded I relax the bounds constraint to “somewhere between bounds
and bounds*2”. This allows me to eliminate a lot of coordination between
readers and writers by using a single reader to unblock up to bounds number
of writers. This constraint (along with the constraint that bounds be a power
of two, for fast modulo) seemed like something everyone could live with.
I also guess that this “cohort unblocking” behavior could result in some nicer stride behavior, with more consecutive non-blocking reads and writes, rather than having a situation where the queue is almost always either completely full or empty.
One-shot MVars and Semaphores
This has nothing to do with queues, but just a place to put this observation:
garbage-collected languages permit some interesting non-traditional concurrency
patterns. For instance I use MVars and IORefs that only ever go from empty
to full, or follow a single linear progression of three or four states in their
lifetime. Often it’s easier to design algorithms this way, rather than by using
long-lived mutable variables (for instance I struggled to come up with a
blocking bounded queue design that used a circular buffer which could be made
async-exception-safe).
Similarly the CAS operation (which I get exported from
atomic-primops)
turns out to be surprisingly versatile far beyond the traditional
read/CAS/retry loop, and to have very useful semantics when used on short-lived
variables. For instance throughout unagi-chan I do both of the following:
-
CAS without inspecting the return value, content that we or any other competing thread succeeded.
-
CAS using a known initial state, avoiding an initial read