17x17: A Simulated Annealing approach using thresholds
Last updated: Jan 2, 2025
Note: this is part of a series of posts is related to the “17x17 Challenge” posted by Bill Gasarch. The goal is to color cells of a 17 by 17 grid, using only four colors, such that no rectangle is formed from four cells of the same color.
This is something I’ve been wanting to play with for months now, but haven’t made the time to implement: I wondered if simulated annealing techniques could be effective in finding a complete grid covering.
We would simply start with four copies of the 74-color grid and swap their rows and columns around, within each color set, trying to cover all of the cells by the union of the four subsets. So all of the sets of cells of a single color are fundamentally simply different permutations of the same 74-cell rectangle-free Graph.
Here is an illustration of the concept. Our algorithm starts with all four colored sets of cell overlapping (the red cells are on top, covering the other three colors):
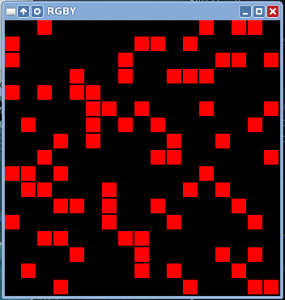
…then we swap two rows or two columns from a colored subset of cells, until the four colored subsets spread out covering as much of the grid as possible. Here we cover all but 21 cells:

A Brief Intro to Simulated Annealing
Simulated Annealing is a bit of an intimidating term (has its origins in metallurgy of all things), but the idea is simple: you start off with an initial solution (in my case, four sets of cells, all of which overlap) and then you mutate it randomly by choosing a random “neighbor” solution (in my case, a grid in which two rows or two columns of the same color are swapped).
You score these solutions so that you can compare a current solution with a proposed mutated solution, and here’s the key:
You begin by accepting nearly every mutation, whether it improves your solution or not. But as the procedure progresses you become more picky about “how much worse” a new solution can be from the previous one.
So in the classic Traveling Salesman Problem a neighbor solution would be a new route that goes from city C to city E, where in the last solution we went from city E to city C.
Threshold Acceptance
There are various ways of accomplishing the task of “ratcheting down” the computation over time. The traditional method (the method most matching the metallurgical metaphor, if you will) is to have a function that computes the probability of a proposed change being accepted. This probability function changes over time, such that as we progress it becomes more and more unlikely that a solution worse than the previous will be accepted.
Another method, and the one I chose to implement, seems to be referred to as Threshold Accepting; instead of having a probability function, you accept all mutations that are below a certain threshold of change from the previous solution. The threshold becomes more strict over time.
So in our case we might start off with a threshold of five, meaning that we will accept all changes that give us a worse solution of no more than 5 new un-colored cells. So for example: if swapping blue rows 5 and 12 create a new solution with 6 fewer colored (covered) cells from the previous solution (i.e. a worse solution by six), then it won’t be accepted by our meta-algorithm at this stage.
Notes on the implementation
The approach I tried to describe above was really attractive to me because it short-circuits the whole complex “rectangle-free” constraint entirely. We simply start with a known rectangle-free subset and see if we can make four copies fit together.
Also, because we swap two rows or columns at a time, we need only look at the local change of score produced by the swap and then add it to the global score to obtain the new global score.
The astronomical number (17!^2) of possible permutations of a single
rectangle-free subset give me hope that this approach could work, but that is
an open question as far as I know.
I wrote this first draft of the script in haskell (as usual), and was happy
with how fast it is, thanks in large part to the
vector library,
which was a pleasure to work with. The code uses 4 pairs of Vectors (arrays
of Ints), 8 in total, each of which represent a row or column ordering of one
of the four colors.
We store the original 74-cell rectangle-free subset as a 2D Array (Int,Int) Bool. The pairs of Vectors act as references to row or column slices of this
2D array.
When we want to score a swap, we have to “render” all four colors of the pair of rows/columns in question using our 2D reference array. Then a swap consists of swapping two Ints in a single Vector. This is much more friendly on more poor laptop than if we were to try storing all four color subsets as 2D arrays and swapping them around!
You can download the code here, but mind it isn’t incredibly pretty.
Initial findings
The best I’ve done with this initial version is a grid with 19 empty cells:

It is obvious though that the heuristic needs a lot of tuning, and that in my case the “Threshold Accepting” approach isn’t working well. That is because it is far too granular: we get from complete disorder to a minimum in just a handful of threshold rounds.
Here is a quick graph overlaying two runs, one of which starts with a threshold (each threshold round bracketed in black) of 5, the other (in blue) starts with a threshold of 2. The Y-axis is the number of uncolored cells in the grid at the current solution:
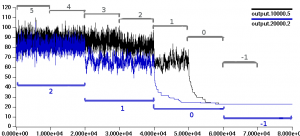
You can see that both basically look like random Brownian walks during the course of a threshold round, and quickly drop to a lower energy level (better solution) as soon as the threshold is tightened. Most dramatic is the jump when we go from 2 to 1.
This looks like we’re being thrust into a local minima, which is the opposite of what we want here. But whether a more finely-tuned annealing schedule can do better is anyone’s guess.
What’s next?
It should be very simple to implement a more traditional annealing procedure that would ease us into lower “energy levels” without the harsh dives we get from using only a handful of threshold levels. So that is what is next on the agenda for this problem.
If this annealing business looks promising after I master the black art of “tuning the meta-heuristic”, it would be cool to come up with a single- coloring algorithm, capable of generating rectangle free colorings of 72,73, or 74 cells. We would then feed those solutions into our annealing framework, finding the best combinations of colorings via a genetic algorithm or the like.
But that leads to the question I’ve posed earlier: it is sometimes trivial to determine if two colorings are “unique” (i.e. by counting colored cells in rows and columns); but when it isn’t trivial, determining whether two colorings are “equivalent” seems to be a very difficult problem.
What a hole I’ve fallen into…